datahoarder
6729 readers
12 users here now
Who are we?
We are digital librarians. Among us are represented the various reasons to keep data -- legal requirements, competitive requirements, uncertainty of permanence of cloud services, distaste for transmitting your data externally (e.g. government or corporate espionage), cultural and familial archivists, internet collapse preppers, and people who do it themselves so they're sure it's done right. Everyone has their reasons for curating the data they have decided to keep (either forever or For A Damn Long Time). Along the way we have sought out like-minded individuals to exchange strategies, war stories, and cautionary tales of failures.
We are one. We are legion. And we're trying really hard not to forget.
-- 5-4-3-2-1-bang from this thread
founded 4 years ago
MODERATORS
1
2
3
4
5
6
7
8
9
10
11
12
13
20
Requesting assistance/guidance archiving: Accord's Library, a site that archived and translated Yoko Taro works
(lemmy.dbzer0.com)
Yoko Taro is the creative director behind the Nier and Drakengard series, and he has released a lot of supplemental material across a variety of mediums over the years in Japan. Accord's Library is a site that is dedicated to finding this material, archiving it, and translating it.
Today, in Accord's Library Discord, they announced that they received a Cease and Desist from Square-Enix, and on Oct 31, the Library and Gallery sections of the site will be closed and taken offline.
Announcement Screenshot
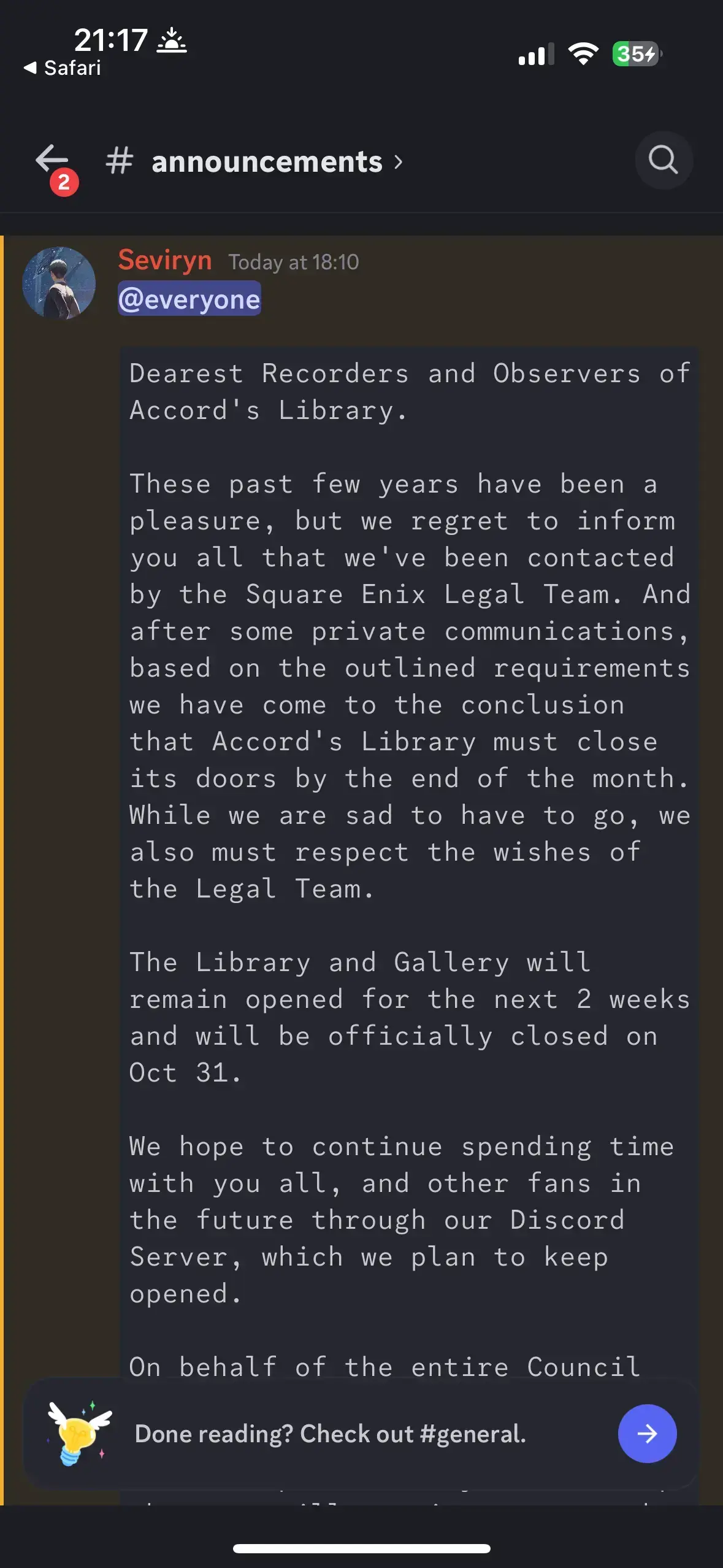
Announcement Text
Dearest Recorders and Observers of Accord's Library.
These past few years have been a pleasure, but we regret to inform you all that we've been contacted by the Square Enix Legal Team. And after some private communications, based on the outlined requirements we have come to the conclusion that Accord's Library must close its doors by the end of the month. While we are sad to have to go, we also must respect the wishes of the Legal Team.
The Library and Gallery will remain opened for the next 2 weeks and will be officially closed on Oct 31.
We hope to continue spending time with you all, and other fans in the future through our Discord Server, which we plan to keep opened.
On behalf of the entire Council for Accord's Library, we sincerely thank you for your support and friendship over the years. We hope that you will continue to use the discord, though we understand if this is where we part ways.
From the very bottom of our hearts, we will be forever grateful to everyone who's volunteered their time to help build Accord's Library into what it was. Thank you to all of our Transcribers, Translators, and most of all, all of you for sticking with us.
Take care of yourselves out there. Glory to Mankind.
- The Accord's Library Council
If anyone is skilled with backing up sites, any assistance would be appreciated. Even if it's just to point at the right tool for the job (been almost a decade since I've backed up part of a site).
Shoutout to !helloharu@lemmy.world making the original post.
14
15
16
17
18
19
20
21
22
23
24
25
view more: next ›