I keep getting an error ValueError: perm should have the same length as rank(x): 3 != 2 when trying to convert my model using coremltools.
From my understanding the most common case for this is when your input shape that you pass into coremltools doesn't match your model input shape. However, as far as I can tell in my code it does match. I also added an input layer, and that didn't help either.
I have put a lot of effort into reducing my code as much as possible while still giving a minimal complete verifiable example. However, I'm aware that the code is still a lot. Starting at line 60 of my code is where I create my model, and train it.
I'm running this on Ubuntu, with NVIDIA setup with Docker.
Any ideas what I'm doing wrong?
from typing import TypedDict, Optional, List
import tensorflow as tf
import json
from tensorflow.keras.optimizers import Adam
import numpy as np
from sklearn.utils import resample
import keras
import coremltools as ct
# Simple tokenizer function
word_index = {}
index = 1
def tokenize(text: str) -> list:
global word_index
global index
words = text.lower().split()
sequences = []
for word in words:
if word not in word_index:
word_index[word] = index
index += 1
sequences.append(word_index[word])
return sequences
def detokenize(sequence: list) -> str:
global word_index
# Filter sequence to remove all 0s
sequence = [int(index) for index in sequence if index != 0.0]
words = [word for word, index in word_index.items() if index in sequence]
return ' '.join(words)
# Pad sequences to the same length
def pad_sequences(sequences: list, max_len: int) -> list:
padded_sequences = []
for seq in sequences:
if len(seq) > max_len:
padded_sequences.append(seq[:max_len])
else:
padded_sequences.append(seq + [0] * (max_len - len(seq)))
return padded_sequences
class PreprocessDataResult(TypedDict):
inputs: tf.Tensor
labels: tf.Tensor
max_len: int
def preprocess_data(texts: List[str], labels: List[int], max_len: Optional[int] = None) -> PreprocessDataResult:
tokenized_texts = [tokenize(text) for text in texts]
if max_len is None:
max_len = max(len(seq) for seq in tokenized_texts)
padded_texts = pad_sequences(tokenized_texts, max_len)
return PreprocessDataResult({
'inputs': tf.convert_to_tensor(np.array(padded_texts, dtype=np.float32)),
'labels': tf.convert_to_tensor(np.array(labels, dtype=np.int32)),
'max_len': max_len
})
# Define your model architecture
def create_model(input_shape: int) -> keras.models.Sequential:
model = keras.models.Sequential()
model.add(keras.layers.Input(shape=(input_shape,), dtype='int32', name='embedding_input'))
model.add(keras.layers.Embedding(input_dim=10000, output_dim=128)) # `input_dim` represents the size of the vocabulary (i.e. the number of unique words in the dataset).
model.add(keras.layers.Bidirectional(keras.layers.LSTM(units=64, return_sequences=True)))
model.add(keras.layers.Bidirectional(keras.layers.LSTM(units=32)))
model.add(keras.layers.Dense(units=64, activation='relu'))
model.add(keras.layers.Dropout(rate=0.5))
model.add(keras.layers.Dense(units=1, activation='sigmoid')) # Output layer, binary classification (meaning it outputs a 0 or 1, false or true). The sigmoid function outputs a value between 0 and 1, which can be interpreted as a probability.
model.compile(
optimizer=Adam(),
loss='binary_crossentropy',
metrics=['accuracy']
)
return model
# Train the model
def train_model(
model: tf.keras.models.Sequential,
train_data: tf.Tensor,
train_labels: tf.Tensor,
epochs: int,
batch_size: int
) -> tf.keras.callbacks.History:
return model.fit(
train_data,
train_labels,
epochs=epochs,
batch_size=batch_size,
callbacks=[
keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=5),
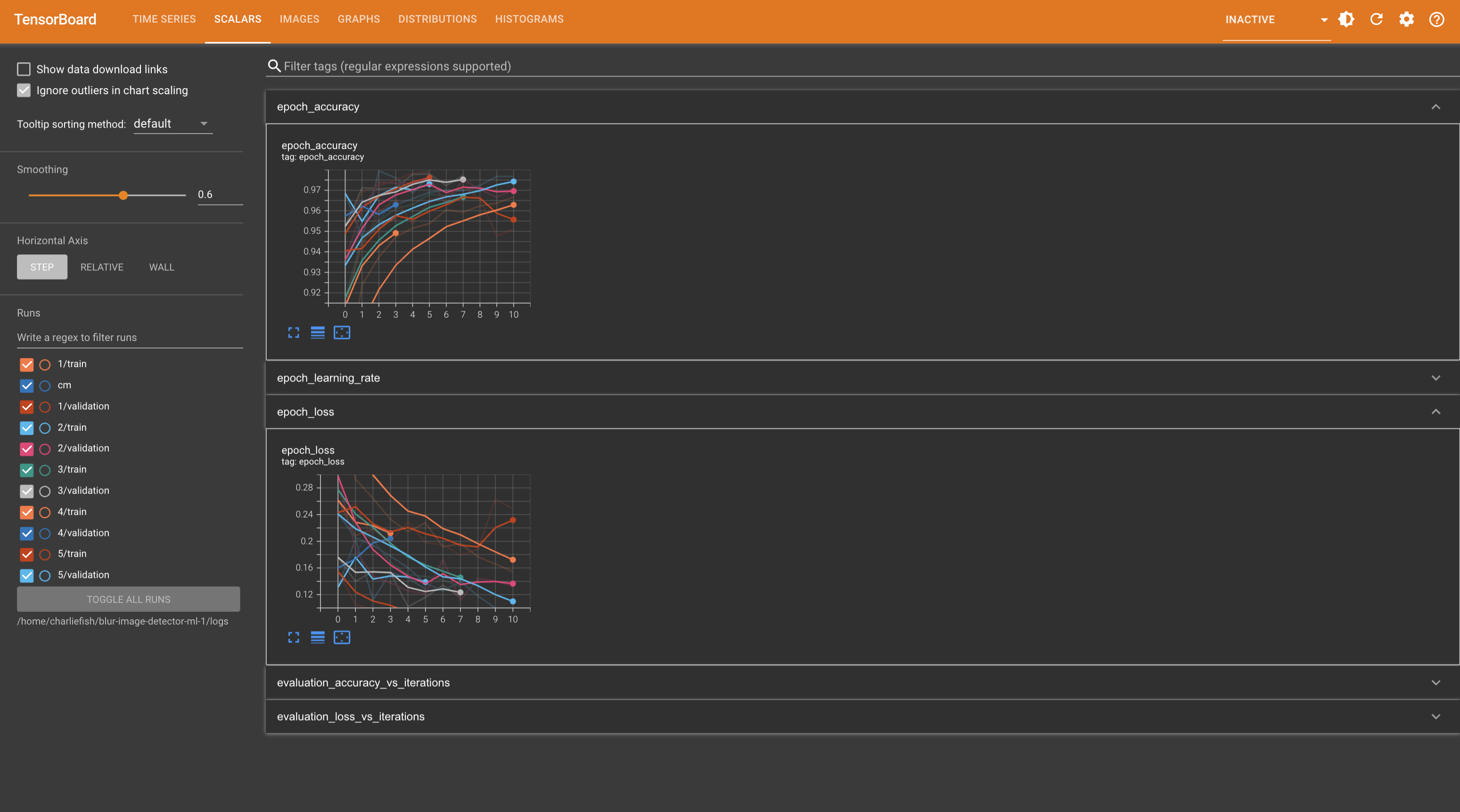
keras.callbacks.TensorBoard(log_dir='./logs', histogram_freq=1),
# When downgrading from TensorFlow 2.18.0 to 2.12.0 I had to change this from `./best_model.keras` to `./best_model.tf`
keras.callbacks.ModelCheckpoint(filepath='./best_model.tf', monitor='val_accuracy', save_best_only=True)
]
)
# Example usage
if __name__ == "__main__":
# Check available devices
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
with tf.device('/GPU:0'):
print("Loading data...")
data = (["I love this!", "I hate this!"], [0, 1])
rawTexts = data[0]
rawLabels = data[1]
# Preprocess data
processedData = preprocess_data(rawTexts, rawLabels)
inputs = processedData['inputs']
labels = processedData['labels']
max_len = processedData['max_len']
print("Data loaded. Max length: ", max_len)
# Save word_index to a file
with open('./word_index.json', 'w') as file:
json.dump(word_index, file)
model = create_model(max_len)
print('Training model...')
train_model(model, inputs, labels, epochs=1, batch_size=32)
print('Model trained.')
# When downgrading from TensorFlow 2.18.0 to 2.12.0 I had to change this from `./best_model.keras` to `./best_model.tf`
model.load_weights('./best_model.tf')
print('Best model weights loaded.')
# Save model
# I think that .h5 extension allows for converting to CoreML, whereas .keras file extension does not
model.save('./toxic_comment_analysis_model.h5')
print('Model saved.')
my_saved_model = tf.keras.models.load_model('./toxic_comment_analysis_model.h5')
print('Model loaded.')
print("Making prediction...")
test_string = "Thank you. I really appreciate it."
tokenized_string = tokenize(test_string)
padded_texts = pad_sequences([tokenized_string], max_len)
tensor = tf.convert_to_tensor(np.array(padded_texts, dtype=np.float32))
predictions = my_saved_model.predict(tensor)
print(predictions)
print("Prediction made.")
# Convert the Keras model to Core ML
coreml_model = ct.convert(
my_saved_model,
inputs=[ct.TensorType(shape=(max_len,), name="embedding_input", dtype=np.int32)],
source="tensorflow"
)
# Save the Core ML model
coreml_model.save('toxic_comment_analysis_model.mlmodel')
print("Model successfully converted to Core ML format.")
Code including Dockerfile & start script as GitHub Gist: https://gist.github.com/fishcharlie/af74d767a3ba1ffbf18cbc6d6a131089


This is not a “mistake”. This clearly proves they have Apple TV app integration implemented (just turned off). And someone accidentally turned it on.
But they have clearly put in effort and work into adding this functionality.
New functionality doesn’t just happen by mistake.